![]()
작성일: 2013.09.19
|
FPGA와 CPU는 오랜 기간 동안 레이더 신호 처리의 필수 부품이었다. FPGA는 전통적으로 프론트-엔드 처리를 위해 사용되었으며, CPU는 백-엔드 처리를 위해 사용되었다. 레이더 시스템의 성능과 복잡성이 증가함에 따라 처리 요구사항들이 극적으로 증가했다. FPGA는 증가하는 처리 성능과 쓰루풋에 보조를 맞춰 왔지만, CPU는 차세대 레이더에서 요구하는 신호 처리 성능을 제공하는 데 어려움을 겪어 왔다. 이러한 어려움으로 인해 무거운 처리 부하를 지원하기 위해 GPU(graphic processing unit) 등과 같은 CPU 액셀러레이터의 사용이 증가했다.
최고 GFLOPs 등급
현재의 FPGA는 1 이상의 최고 TFLOPs 성능을 제공하는 반면, AMD와 Nvidia의 최신 GPU는 한층 더 높은 최대 4TFLOP까지의 성능을 제공하는 것으로 평가되고 있다. 하지만, 최고 GFLOPs 또는 TFLOPs는 특정 애플리케이션에서의 해당 디바이스가 제공하는 성능에 대해 최소한의 정보만을 제공한다. 이것은 단지 초 당 수행될 수 있는 이론적인 부동소수점 덧셈 또는 곱셈의 전체 수만을 표시할 뿐이다. 이 분석결과는 FPGA가 1 TFLOPs의 단정도(single-precision) 부동소수점 처리 성능을 초과할 수 있다는 것을 보여준다.
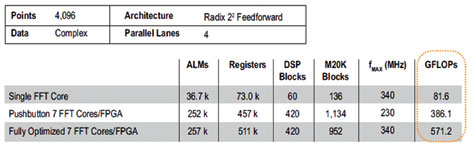
중간 정도의 복잡성을 가진 일반적인 알고리즘은 고속 푸리에 변환(fast Fourier transform, FFT)이다. 대부분의 레이더 시스템들이 주파수 영역에서 많은 처리 기능을 수행하기 때문에 FFT 알고리즘을 주로 사용한다. 예를 들어, 4,096-포인트 FFT는 단정도 부동소수점 처리 기능을 통해 구현되어왔다. 이것은 클록 사이클 당 4개의 복잡한 샘플을 입출력할 수 있다. 각각의 단일 FFT 코어는 80GFLOPs 이상의 속도로 동작할 수 있으며, 대형 28nm FPGA를 사용하여 이와 같은 코어 7개를 구현할 수 있다. 하지만, 그림 1에 제시된 바와 같이 이러한 FPGA상의 FFT 알고리즘은 거의 400GFLOPs의 성능을 제공한다. 이러한 결과는 FPGA에 대한 전문지식을 전혀 사용하지 않는 ‘푸쉬 버튼(push button)’ OpenCL 컴파일링에 기반하고 있다. 로직-락(logic-lock) 및 DES(Design Space Explorer)를 이용한 최적화를 사용할 경우, 7-코어 설계는 단일-코어 설계의 fMAX에 근접할 수 있으며, 28nm FPGA를 사용해 이를 10GFLOPs/W 이상을 제공하는 최대 500GFLOPs 이상의 성능으로 증대시킬 수 있다. 이러한 GFLOPs/W 결과는 CPU 또는 GPU를 통해 달성 가능한 전력 효율보다 한층 더 높은 것이다. GPU는 이러한 FFT 길이에서 비효율적이기 때문에 GPU 비교 결과에 대한 벤치마크 자료는 제시하지 않았다. CPU에 대해 유용한 가속 기능을 제공할 수 있을 경우, GPU는 수백만 포인트의 FFT 길이에서 효율적이다.
하지만, 보다 짧은 FFT 길이가 레이터 처리에 주로 사용되며, 512에서 8,192까지의 FFT 길이가 일반적이다. 요약하면, 유용한 GFLOPs는 대개의 경우에 최고 또는 이론적인 GFLOPs의 일부이다. 이러한 이유 때문에 보다 나은 접근법은 일반적인 애플리케이션들의 특성들을 적절하게 나타낼 수 있는 알고리즘과 함께 성능을 비교하는 것이다. 벤치마크한 알고리즘의 복잡성이 증가함에 따라 실질적인 레이더 시스템의 성능을 보다 잘 표현할 수 있다.
Figure 1. Stratix V 5SGSD8 FPGA Floating-Point FFT Performance
써드파티 벤치마킹
처리 기술 의사결정을 진행하는 데 있어서 공급업체의 최고 GFLOPs 등급을 사용하기 보다는 그 대안으로서 충분한 복잡성을 가진 예제들을 사용한 써드파티 평가 결과를 사용할 수 있다. STAP(space-time adaptive processing) 레이더를 위한 일반적인 알고리즘은 촐레스키 분해(Cholesky decomposition)이다. 이 알고리즘은 다중 방정식의 효율적인 해법을 위해 선형대수학(linear algebra)에서 일반적으로 사용되며, 상관행렬(corre-lation matrix)에서도 사용될 수 있다.
촐레스키 알고리즘은 높은 수학적 복잡성을 가지고 있으며, 적정한 결과를 위해 거의 항상 부동소수점을 이용한 수치적 표현을 요구한다. 요구되는 연산은 N3에 비례하며, 여기서 N은 매트릭스 차수이며 따라서 처리 요구사항이 일반적으로 높아진다. 레이더 시스템은 일반적으로 실시간으로 동작하기 때문에 높은 쓰루풋이 요구사항의 하나이다. 결과는 매트릭스 크기와 요구되는 매트릭스 처리 쓰루풋 모두에 따라 달라질 수 있지만, 일반적으로 100GFLOPs 이상이 될 수 있다.
표 1은 다양한 라이브러리를 사용한 1.35 TFLOPs 속도의 Nvidia GPU와 475K LC의 집적도를 통해 DSP 처리 기능에 최적화된 FPGA인 Xilinx Virtex6 XC6VSX475T에 기반 한 벤치마킹 결과를 나타낸 것이다. 이들 디바이스들은 촐레스키 벤치마크를 위해 사용된 알테라 FPGA와 집적도에 있어서 유사하다. LAPACK과 MAGMA은 상업적으로 공급되는 라이브러리이지만, GPU GFLOPs는 테네시대학교에서 개발된 OpenCL 구현방법을 참고했다. 후자가 상대적으로 작은 매트릭스 크기에서 분명히 한층 더 최적화되었다.
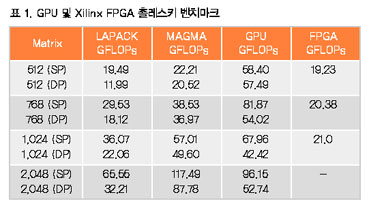
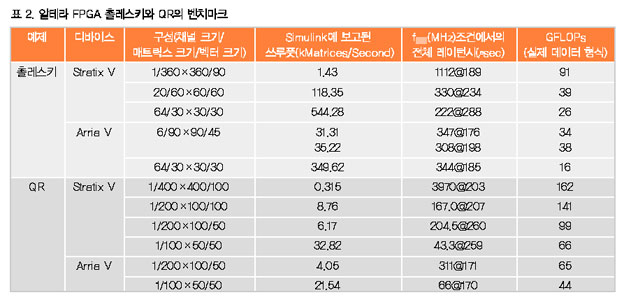
BDTI가 단정도 부동소수점 처리 기능에서 촐레스키 알고리즘을 사용하여 중형 알테라 Stratix® V FPGA (460K LE)를 벤치마킹했다. 표 2에 나타난 바와 같이 촐레스키 알고리즘 상의 Stratix V FPGA 성능이 Xilinx의 결과보다 한층 더 높다.
벤치마크들의 행렬 크기가 동일하지 않다는 것에 주의할 필요가 있다. 테네시 대학교의 결과는 [512 x 512]의 행렬 크기에서 시작한 반면, BDTI의 벤치마크는 최대 [360 x 360]까지이다. 그 이유는 GPU가 상대적으로 작은 행렬 크기에서 매우 비효율적이어서 이러한 사례에서 CPU를 가속화시키기 위해 이들을 사용하는 것이 다소 유리하기 때문이다. 반면, FPGA는 한층 더 작은 행렬에서 효율적으로 동작할 수 있다. 이러한 효율이 중요한 레이더 시스템은 초 당 수천 개의 행렬을 처리할 수 있는 상당히 높은 쓰루풋을 요구하기 때문이다. 따라서 심지어 처리를 위해 보다 큰 행렬들을 상대적으로 작은 행렬로 타일링(tiling)해야 할 때에도 보다 작은 크기를 사용한다.
뿐만 아니라, BDTI 벤치마크는 촐레스키 코어에 대한 것이다. 파라미터화가 가능한 각각의 촐레스키 코어를 통해 행렬 크기, 벡터 크기, 채널 수를 선택할 수 있다. 벡터 크기가 FPGA 자원을 대략적으로 결정한다. 상대적으로 큰 [360 x 360] 행렬 크기는 상대적으로 큰 벡터 크기를 사용하여 91GFLOPs 조건에서 이 FPGA에서 단일 코어를 사용할 수 있도록 할 수 있다. 상대적으로 작은 [60 x 60] 행렬은 보다 적은 자원을 사용하기 때문에 총 2 x 39 = 78GFLOPs를 위해 2개의 코어로 실현할 수 있다. 가장 작은 [30 x 30] 행렬 크기는 3 x 26 = 78GFLOPs를 위해 3개의 코어를 지원한다.
FPGA가 대부분의 레이더 시스템에 해당하는 상대적으로 작은 데이터 크기를 가진 문제들에 한층 더 적합해 보일 수 있다. GPU의 효율이 감소하는 연산 부하는 NS만큼, 데이터 I/O는 N2만큼 증가하기 때문이며, 결과적으로 데이터세트가 증가함에 따라 GPU의 I/O 병목현상 문제는 약화된다. 뿐만 아니라, 행렬 크기가 증가함에 따라 행렬 당 처리 수가 증가하여 초당 행렬 쓰루풋이 많이 감소하게 된다. 이와 동시에 쓰루풋이 너무 낮아져서 레이터 시스템의 리얼-타임 요구사항을 만족할 수 없을 것이다.
FFT의 경우, 연산 부하가 N log2 N로 증가하는 데 여기서 데이터 I/O는 N만큼 증가한다. 다시 말해, 매우 큰 데이터 크기 조건에서는 GPU가 효율적인 연산 엔진이다. 반면, FPGA는 모든 데이터 크기 조건에서 효율적인 연산 엔진이며, FFT 크기가 중간 정도이지만 쓰루풋은 매우 중요한 대부분의 레이더 애플리케이션에 보다 적합하다.
GPU 및 FPGA 설계 방법론
GPU는 Nvidia의 전용 CUDA 언어 또는 개방형 표준인 OpenCL 언어를 사용하여 프로그램된다. 이들 언어들은 성능 측면에서 매우 유사하지만, 가장 큰 차이는 CUDA는 Nvidia의 GPU에서만 사용할 수 있다는 것이다. FPGA는 일반적으로 HDL 언어인 Verilog 또는 VHDL을 사용하여 프로그램한다. 최신 버전들이 필요하지 않은 신세시스를 통한 부동소수점 수치들에 대한 정의를 통합하고 있을지라도 이러한 언어들은 부동소수점 설계를 지원하는 데 적합하지 않다. 예를 들어, System Verilog의 경우에 짧은 실변수(short real variable)는 IEEE 단정밀도(부동소수점)에 대해 아날로그이지만, IEEE 배정밀도에 대해서는 실수이다.
DSP Builder Advanced Blockset
Xilinx Floating-Point Core Gen 기능들을 사용하여 구현된 촐레스키 알고리즘 상에서 Xilinx FPGA의 낮은 성능을 통해 확인한 바와 같이 전통적인 방법을 사용하여 FPGA에 부동소수점 데이터경로를 신세시스하는 것은 매우 비효율적이다. 하지만, 알테라는 2가지 대안적인 방법을 제공한다. 첫 번째는 Mathworks 기반 설계 입력 방법인 DSP Builder Advanced Blockset을 사용하는 것이다. 이 툴은 고정 및 부동소수점 숫자들에 대한 지원 기능을 포함하고 있으며, IEEE 반정밀도, 단정도, 배정밀도 구현방법 등을 포함해 7개의 각기 다른 정밀도의 부동소수점 처리 기능을 지원한다.
이것은 또한 선형대수학의 효율적인 구현을 위해 필요한 벡터화(vectorization)를 지원한다. 중형 28nm FPGA에서 촐레스키 알고리즘 상에서 100GFLOPs에 근접한 성능을 지원하는 벤치마킹 결과를 통해 검증된 바와 같이 가장 중요한 것은 부동소수점 회로를 효율적으로 현재의 고정소수점 FPGA 아키텍처에 맵핑할 수 있는 능력이다. 비교를 통해 이러한 신세시스 성능이 없는 유사한 크기의 Xilinx FPGA 상에서 촐레스키 구현 시 동일한 알고리즘 상에서 단지 20GFLOPs 성능만을 제공한다.
FPGA를 위한 OpenCL
OpenCL은 GPU 프로그래머들에게 친숙하다. FPGA를 위한 OpenCL Compiler는 AMD 또는 Nvidia GPU를 위해 작성된 OpenCL 코드를 FPGA로 컴파일링할 수 있다는 것을 의미한다. 뿐만 아니라, 알테라의 OpenCL Compiler는 일반적인 FPGA 설계 기술 세트를 개발할 필요 없이 GPU 프로그램들이 FPGA를 사용할 수 있도록 지원한다.
FPGA와 함께 OpenCL을 사용하는 것은 GPU 대비 몇 가지 주요한 장점을 제공한다. 첫 번째, GPU는 I/O에 의해 제한되는 경향이 있다. 모든 입력 및 출력 데이터가 PCIe®(PCI Express®) 인터페이스를 통해 호스트 CPU를 통과해야만 한다. 결과적인 지연이 GPU 처리 엔진을 지연시켜 성능을 감소시키게 된다.
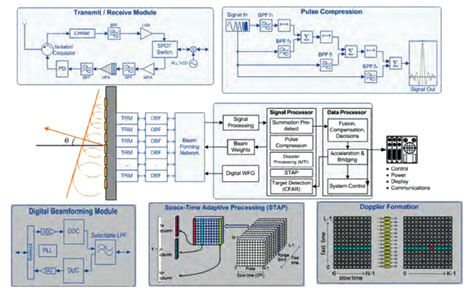
Figure 2. Generic Radar Signal Processing Diagram
FPGA를 위한 OpenCL 확장 기능
FPGA는 다양한 고대역폭 I/O 성능을 제공하는 것으로 알려져 있다. 이러한 성능들은 GbE(Gigabit Ethernet), SRIO(Serial RapidIO®)을 통해서 또는 ADC(analog-to-digital converter) 및 DAC(digital-to-analog converter)로부터 직접적으로 FPGA 내부와 외부로 데이터가 흐를 수 있도록 지원한다. 알테라는 스트리밍 동작을 지원하기 위해 OpenCL 표준에 대한 벤더-지정 확장 기능을 정의했다. 이 확장 기능은 레이더 시스템에서 중요한 기능인 데 이를 통해 데이터가 고정소수점 프론트-엔드 빔포밍(beamforming)에서부터 디지털 하향변환(down-conversion) 처리, 펄스 압축, Doppler, STAP, MTI (moving target indicator), 그리고 그림 2에 나타낸 그 외 기능들을 위한 부동소수점 처리 단까지 이동할 수 있기 때문이다. 이러한 방법을 통해 CPU 액셀러레이터를 통과하기 전에 나타나는 데이터 플로의 CPU 병목 현상을 방지하여 전체 처리 지연을 줄일 수 있다.
FPGA는 또한 심지어 I/O 병목 현상에 상관없이 GPU보다 한층 더 낮은 처리 지연 특성을 제공할 수 있다. 메모리와 심지어 CPU의 많은 처리 코어 사이의 매우 긴 지연으로 인해 GPU가 효율적으로 수행하기 위해서는 수천 개의 쓰레드 상에서 동작해야 한다는 것은 잘 알려져 있다. 사실상 GPU는 해당 태스크에 대해 매우 긴 지연을 일으키는 데이터 대기로 인한 처리 코어의 지연을 방지하기 위해서 많은 태스크들을 처리해야만 한다.
FPGA는 '조립(coarse-grained) 병렬' 아키텍처를 대신 사용한다. 이것은 복수의 최적화된 병렬 데이터경로를 생성하며, 이 각각은 클록 사이클 당 1개의 결과를 출력한다. 데이터경로의 인스턴스 수는 FPGA 자원에 의해 결정되지만, 일반적으로 GPU 코어의 수보다는 훨씬 적다. 하지만, 각 데이터경로 인스턴스는 GPU보다 한층 더 높은 쓰루풋을 제공한다. 이러한 접근법의 주요한 장점은 낮은 지연 특성으로 이것은 많은 애플리케이션에서 중요한 성능 이점을 제공한다.
FPGA의 또 다른 장점은 전력소모가 한층 더 낮기 때문에 GFLOPs/W가 극적으로 낮아진다는 것이다. BDTI가 측정한 바에 따르면 복잡한 부동소수점 알고리즘(촐레스키 등과 같은)에 대한 GFLOPs/W가 5-6GFLOPs/W.
GPU의 에너지 효율 측정결과를 찾기는 매우 어렵지만, 촐레스키를 위해 50GFLOPs의 GPU 성능과 200W의 일반적인 전력소모 특성을 사용할 경우에 결과는 0.25GFLOPs/W가 되며, 이것은 유효 FLOPs 당 소모된 전력의 20배가 된다. 에어본 또는 차량-실장 레이더의 경우, 크기, 무게, 전력(SWaP, size, weight, and power) 고려사항이 다른 무엇보다 중요하다. 미래 시스템에서 수십 TFLOPs의 성능을 가진 레이더 탑재 소형 무인 정찰기를 예를 들어보자. 이용 가능한 처리 전력의 양에 따라 최신 레이더 시스템이 제공할 수 있는 해상도와 커버리지가 달라질 것이다.
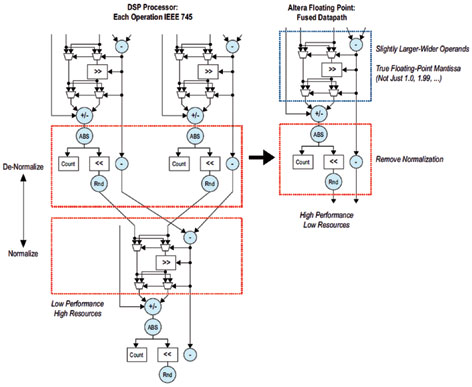
융합 데이터경로
OpenCL와 DSP Builder 모두 '융합 데이터경로(fused datapath)' (그림 3)로 알려진 기법을 사용하는 데 이것은 부동소수점 처리 기능을 요구되는 배럴-시프팅(barrel-shifting) 회로의 수를 극적으로 낮추는, 다시 말해 대형 고성능 부동소수점 설계를 FPGA를 사용하여 구축할 수 있도록 지원하는 이와 같은 방법으로 구현하는 것이다. 신세시스 과정은 배럴 시프팅을 실행하는 빈도를 낮추기 위해서 보다 큰 가수(mantissa) 폭을 사용하여 빈번한 정규화 및 역정규화에 대한 요구를 상쇄시킬 수 있는 기회를 찾는다. 27×27 및 36×36 하드 곱셈기를 사용하여 단정도 구현 시 요구되는 23bit보다 한층 더 큰 곱셈기를 사용할 수 있으며, 54×54 및 72×72 곱셈기 구성을 통해 배정밀도 구현을 위해 요구되는 52bit보다 큰 곱셈기를 구현할 수 있다.
FPGA 로직은 빌트-인 CLA(carry look-ahead) 회로를 포함하는 대형 고정소수점 덧셈기 회로 구현을 위해 이미 최적화되어 있다.
Figure 3. Fused Datapath Implementation of Floating-Point Processing
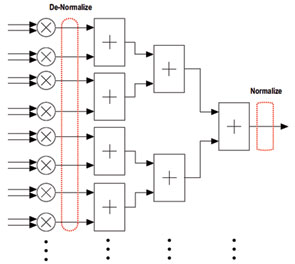
정규화 및 비정규화가 요구될 경우, 성능 저화와 과도한 라우팅을 방지할 수 있는 대안적인 구현방법은 곱셈기를 사용하는 것이다. 24bit 단정도 가수(신호 bit 포함)의 경우, 24×24 곱셈기가 2n을 곱하여 입력을 시프트시킨다. 다시 말해, 27×27 및 36×36 하드 곱셈기를 통해 단정도 구현 시 가수 크기를 확장시킬 수 있으며, 배정밀도 구현을 위한 곱셈기 크기를 구성하는 데에도 사용할 수 있다. 벡터의 내적(vector dot product)은 많은 선형대수학 알고리즘에서 사용되는 대량의 FLOPs를 소모하는 기본 연산이다. 길이 64의 긴 벡터 내적에 대한 단정도 구현을 위해서는 64개의 부동소수점 곱셈기가 필요하며, 다음으로 63개의 부동소수점 덧셈기로 구성된 덧셈기 트리가 온다. 이와 같은 구현 방법은 많은 배럴 시프팅 회로를 요구한다. 대신 64개의 곱셈기 출력을 64개 지수 중 최대값이 되는 공통 지수(common exponent)로 비정규화할 수 있다. 다음으로 이러한 64개의 출력을 고정소수점 덧셈기 회로를 사용하여 합산하고, 덧셈기 트리의 마지막에서 최종 정규화를 수행할 수 있다. 이러한 국지적인 블록 부동소수점 처리를 통해 각각의 덧셈기에서 요구하는 모든 중간 정규화 및 비정규화를 처리할 수 있으며, 이를 그림 4에 나타내었다. 심지어 IEEE 754 부동소수점 처리의 경우에도 최대 지수를 가진 수가 지수를 최종적으로 결정하며, 따라서 이러한 변경을 통해 지수 조정을 계산의 보다 초기 지점으로 이동시킬 수 있다.
Figure 4. Vector Dot Product Optimization
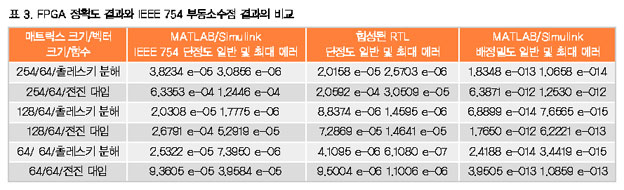
하지만, 신호 처리를 수행할 경우에 연산의 끝에서 결과의 라운딩를 수행할 때 가능한 높은 정밀도로 수행함으로써 최상의 결과를 찾을 수 있다. 이때 이 접근법은 단정도 부동소수점 처리에 의해 요구되는 27bit에서 36bit까지 가수 bit 폭을 추가하여 이러한 차선의 초기 비정규화를 보상한다. 부동소수점 곱셈기를 통해 가수 확장을 수행하여 각 단계의 결과에 대한 정규화 요구를 제거한다. 융합 데이터경로 접근법은 표 3에 제시한 바와 같이 전통적인 IEEE 754 부동소수점 결과보다 정확한 결과를 생성한다. BDTI의 벤치마크 활동과 유사한 결과를 얻을 수 있다. 이러한 결과들은 촐레스키 분해 알고리즘을 사용하여 대형 역행렬(matrix inversion)을 구현하여 얻을 수 있다. 동일한 알고리즘을 다음과 같은 3개의 각기 다른 방법으로 구현할 수 있다:
배정밀도 구현방법이 단정도 구현방법보다 약 10억(109) 배 정확하다.
MATLAB 단정도 에러, RTL 단정도 에러, MATLAB 배정밀도 에러 등을 이와 같이 비교하여 융합 데이터경로 접근법의 무결성을 확인할 수 있다. 이러한 접근법은 출력 행렬과 최대 에러를 가진 행렬 요소의 모든 복합 요소들에 대한 정규화 에러 모두에 대해 나타난다. 전체 에러 또는 수는 프로베니우스의 수를 사용하여 계산한다:
뿐만 아니라, DSP Builder Advanced Blockset과 OpenCL 툴 플로 모두 차세대 FPGA 아키텍처를 위한 현재의 설계를 투명하게 지원하고 최적화시킨다. 아키텍처 혁신과 공정 기술 혁신으로 인해 최고 100GFLOPs/W까지 예상할 수 있다.
요약
이제 고성능 레이더 시스템에 대해 새로운 처리 플랫폼 선택사항이 확보되었다. 한층 향상된 SWaP뿐만 아니라 FPGA는 프로세서 기반 솔루션보다 낮은 레이턴시 특성과 높은 GFLOPs 성능을 제공할 수 있다. 차세대 고성능 연산 최적화 FPGA의 출시와 더불어 이러한 장점들은 한층 더 강화될 것이다.
알테라의 OpenCL Compiler는 GPU 프로그래머들이 이러한 새로운 처리 아키텍처의 장점들을 평가할 수 있는 거의 완벽한 경로를 제공한다. 알테라 OpenCL은 1.2와 호환되며, 완벽한 연산 라이브러리 지원 세트를 제공한다. 이것은 타이밍 클로져, DDR 메모리 관리, PCIe 호스트 프로세서 인터페이스 등과 관련한 전통적인 FPGA의 기술적 과제를 제거한다.
비-GPU 개발자들을 위해서 알테라는 DSP Builder Advanced Blockset 툴 플로를 제공하여 개발자들이 Mathworks 기반 시뮬레이션 및 개발 환경의 장점을 유지하면서 고-fMAX의 고정 또는 부동소수점 DSP 설계를 구축할 수 있도록 지원하고 있다. 이 제품은 FPGA를 사용하는 레이더 개발자들에 의해 수년 동안 사용되어 왔으며, 하드-코드 HDL과 동일한 fMAX 성능을 제공하는 보다 생산적인 워크플로와 시뮬레이션을 지원할 수 있다.
본 기고 글에서는 FPGA와 GPU의 부동소수점 성능과 설계 플로를 비교한다. 지난 수년 동안 CPU는 그래픽 이상의 영역으로 확장하면서 GP-GPU로 알려져 있는 강력한 부동소수점 처리 플랫폼이 되어 높은 최고 FLOPs 속도를 제공하고 있다. 전통적으로 고정소수점 DSP(digital signal processing)를 위해 사용되었던 FPGA가 이제 경쟁력 있는 수준의 부동소수점 처리 성능을 제공함에 따라 백-엔드 레이더 처리 가속을 위한 대안으로서 자리잡아 가고 있다. FPGA의 경우, 많은 검증 가능한 부동소수점 벤치마크 결과들이 40nm와 28nm 모두에 대해 발표되었다. 알테라의 차세대 고성능 FPGA는 인텔의 14nm Tri-Gate 공정을 활용하여 최소 5TFLOPs의 성능을 지원할 예정이다. 이 첨단 반도체 공정을 사용할 경우에 최대 100GFLOPs/W의 성능을 예상할 수 있다. 무엇보다 알테라 FPGA는 GPU를 통해 사용되는 선도적인 프로그래밍 언어인 OpenCL을 현재 지원하고 있다.
![]()
![]() Send to a colleague |
Send to a colleague | ![]() Print this document
Print this document