![]()
작성일: 2014.12.08
아크로닉스 고성능 FPGA 솔루션은 동일한 프로세스 노드(node)로 실행되는 현존 FPGA 솔루션 대비 약 3배에 달하는 작업처리량(throughput)을 선보인다. 아크로닉스 스피드스터(Speedster) FPGA 솔루션은 65nm 프로세스에서 실행되며, 최대 1.5GHz의 성능을 발휘한다. 이런 성능을 가능하게 하는 아크로닉스의 고유 기술을 알아본다.
자료제공│아크로닉스
아크로닉스 FPGA는 picoPIPE 로직 패브릭을 전형적인 I/O 프레임이 둘러싸고 있는 모습으로 구성돼 있다(그림 1참조). 이 프레임은 다른 하이엔드 프로그래머블 디바이스의 주변 환경과 비슷하며, 설정할 수 있는 I/O, SerDes, 클록(clock), PLL 등이 포함돼 있다. 이 프레임은 오프 칩(off-chip) 인터페이스를 제공하며, picoPIPE 코어와 이들 인터페이스 사이에서 경계를 형성한다. 이 코어를 들어가고 나가는 데이터들은 모두 이 프레임을 통과해야 한다.
그림 1.
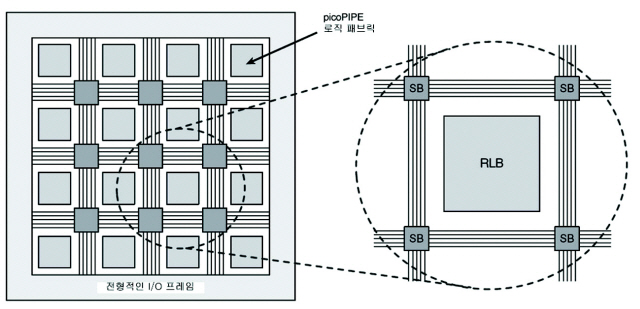
‘블랙 박스’(black box)로 간주될 때, 내부 picoPIPE 패브릭은 전형적인 FPGA 패브릭과 가상적으로 구분되지 않는다. 유일한 차이점은 데이터 작업처리량(throughput)이 현저하게 증대된다는 것이다.
picoPIPE 패브릭은 프로그래밍이 가능한 패브릭으로 연결된 한 개의 RLB (Re-configurable Logic Blocks) 어레이로 구성된다. 각각의 RLB들은 스위치 박스(SB)에 둘러싸여 있다. 스위치 박스는 picoPIPE 패브릭 상에서 글로벌 신호의 루트를 정한다.
각각의 RLB는 8개의 4-인풋(input) LUT(Look Up Table), 스토리지 기본 요소, 128비트 램(RAM) 및 전용 증폭기를 갖고 있다. RLB와 라우팅은 picoPIPE 기술에 기반하지 않은 FPGA에 비해 훨씬 높은 작업처리량을 가능하게 하며 picoPIPE 기술을 활용해 작업한다.
강조할 만한 중요한 개념 중 하나가 ‘데이터 토큰’(Data Token)이다. 전형적인 로직에서 데이터 토큰은 클록 엣지에 있는 로직 가치다. 전통적인 로직 실행에서, 데이터는 항상 존재하지만 클록 엣지가 스토리지 기본요소에서 받아들여질 때만 유효하며 이럴 때 전달된다. 아마도 데이터가 한 스토리지 기본요소에서 다른 곳으로 전달될 때마다, 뚜렷이 구분되고 유효한 데이터 가치 또는 ‘데이터 토큰’만 전달될 것이다.
picoPIPE 단계는 아크로닉스 FPGA 패브릭의 원자 요소다. 이 패브릭은 어떤 로직 기능을 실행하는 데에도 뛰어나다. 로직 기능을 실행하기 위해서 picoPIPE는 글로벌 클록 엣지에 대한 응답으로 데이터를 전달하는 것보다는 뚜렷이 식별되는 데이터 토큰을 활용한다. picoPIPE 로직의 데이터 토큰 한 개는 데이터와 클록 엣지가 합쳐진 것으로 간주할 수 있다. picoPIPE 패브릭이 높은 주파수에서 동작할 수 있도록 하는 핵심적인 혁신 사항이 바로 이처럼 새로운 데이터 토큰의 등장이다.
picoPIPE는 결합요소(Connection Element, CE), 기능요소(Functional Element, FE), 경계요소(Boundary Element, BE), 링크 등의 기본 구성요소들로 구성된다(그림 2참조).
그림 2. picoPIPE 구성 블록

링크는 CE, FE, BE를 연결해 파이프라인 네트웍스를 형성한다(그림 3참조). 일단 네트워크로 묶이게 되면, picoPIPE는 실행 면에 있어서는 전형적인 FPGA의 동작성과 정확히 일치하지만 작업처리량은 훨씬 높은 뛰어난 성능을 발휘한다.
그림 3. picoPIPE 파이프라인 단계

각각의 파이프라인 단계는 데이터 토큰을 보유하는 데 있어서 매우 뛰어나다. 이는 picoPIPE 기술이 설계상으로 매우 높게 파이프라인 되어 있기 때문이다. 전통적인 로직 디자인에서 파이프라인 단계를 추가하는 것은 연산되는 로직 기능을 변화시키는 것이었다. picoPIPE 기술은 이와 다르다. picoPIPE 파이프라인 단계 중 CE와 같은 단계는 새로운 데이터 토큰을 회로에 자동적으로 추가하지 않아도 삽입할 수 있는 것이다. 이는 picoPIPE 기술이 클록과 데이터를 단일 데이터 토큰으로 묶었기 때문에 가능한 것이다.
새로운 데이터 토큰은 따라서 새로운 파이프라인 단계를 단순히 추가만 했을 때는 등장하지 않는다. 이는 파이프라인 단계(또는 CE)가 회로가 연산하는 로직 기능을 바꾸지 않고도 회로 내 어디에든지 삽입될 수 있다는 것을 의미하며, 그 결과 파이프라인 작업이 사용자에게 보다 더 투명하게 된다.
동기화 로직에서 파이프라인 단계(등록/ 스토리지 요소)가 추가될 때, 이는 여전히 반드시 글로벌 클록에서 클록이 돼야만 한다. 이는 자동적으로 로직의 기능성을 변화시키면서 새로운 데이터 토큰을 삽입한다. picoPIPE은 CE를 넣는다고 해서 새로운 데이터 토큰을 삽입하진 않는다. 따라서, 로직이 변화하지 않는다. 파이프라인 단계를 삽입한다고 해도 잠재적인 지연 현상이 조금 발생할 뿐이지만, 그것이 전부다.
CE는 다른 어떤 현존 로직 구조와도 다르다. 이들은 ‘현재 상태 유지’(state holding) 또는 ‘현재 상태 유지 아님’(not state holding) 등 2가지 상태 중 하나로 초기화되는 데 뛰어나다. 현재 상태 유지로 초기화되면, 연결 요소는 전형적인 디자인에서의 ‘레지스터’(register)와 비슷한 동작을 수행하며, 파이프라인 단계를 위해 데이터 토큰이 우선적으로 생성된다. 현재 상태 유지가 아닌 것으로 초기화되면, 이는 리피터(repeater)처럼 행동한다. 초기화되지 않은 일련의 CE와 와이어 사이의 가장 큰 차이점은 각각의 파이프라인 단계가 여전히 데이터 토큰을 포함하는 데 뛰어나다는 것이다. 비록 처음부터 함께 출발하진 않았더라도 말이다. 이런 지적 자산은 예전의 전형적인 회로와 논리적으로는 정확히 똑 같은 것이면서도, 아크로닉스 FPGA가 작업처리량을 증가시키는 데 큰 역할을 수행한다.
FE는 조합로직(combinatorial logic)과 기능성에 있어서 동일하다. 유일한 차이점은 데이터의 진출입을 다루는 방법이다. picoPIPE 내부의 로컬 신호교환(handshake)은 FE가 반드시 데이터를 내외부로 주고받아야 한다고 규정한다. 이런 신호교환 방법론은 유효하고 정착된 데이터만이 전달될 수 있다는 것을 분명히 해 주고 있다.
BE는 picoPIPE 패브릭이 FPGA 프레임을 만나는 경계선에서만 활용된다. 이 요소는 프레임 내의 데이터 토큰을 picoPIPE 패브릭의 데이터 토큰으로 전환하는 역할(진입)을 담당한다. 이들은 또한 패브릭의 데이터 토큰을 다시 프레임 내의 데이터 토큰으로 전환(배출)하는 역할도 담당한다. 따라서, picoPIPE 패브릭을 들어가고 나가는 모든 신호는 진입 BE와 배출 BE를 상대적으로 통과하게 된다.
picoPIPE 단계가 ‘아무런 데이터’도 포함하지 않을 수 있다는 것을 아는 것이 매우 중요하다. 예를 들어, 3개의 유효한 단계는 data-1, data-0, 또는 No-data 등이다. 이는 picoPIPE 단계를 추가해도 연산되는 로직 기능은 바뀌지 않는 이유 중의 하나라 할 수 있다.
picoPIPE 패브릭은 정확히 동일한 행동양식을 통해 동기 로직을 실행한다. 아크로닉스 FPGA와 여러 picoPIPE 기술이 이런 동일함을 가능하게 한다.
FE는 입력 RTL이 제시한 로직을 실행하면서 조합 연산을 제공한다. CE는 동기 연산을 가능하게 하는 연결(로컬 및 글로벌 라우팅)과 스토리지(레지스터)을 제공한다. FPGA 아키텍처에서 스위치 블록이 CE만을 포함하고 있는 것과는 달리, LUT는 FE와 CE를 포함한다.
전형적인 I/O 프레임은 모든 데이터 토큰이 클록 엣지의 picoPIPE 코어로 들어가서, picoPIPE 코어를 떠난 모든 데이터 토큰이 클록 엣지에서 확실하게 클록 아웃되도록 한다. 이런 입력 및 출력의 기능적 상관관계가 RTL에 의해 구체화된 동기 디자인과 프레임 경계 상에서 관측된 실행 기능성 사이에서 유지된다. BE 요소들은 프레임 내의 모든 유효한 데이터 토큰(입력 클록 엣지에서 입력 상의 데이터)가 확실히 picoPIPE 코어 내의 데이터가 될 수 있도록 한다. 출력에서도 마찬가지로, picoPIPE 코어를 떠난 모든 데이터 토큰은 프레임으로 클록되면서(데이터 가치는 코어 밖으로 클록된다) 유효한 데이터 신호가 된다.
picoPIPE 코어를 들어가고 나가는 데이터 토큰의 수는 코어가 전형적인 로직으로 실행될 때의 숫자와 정확히 똑같다.
또 주목할 사항은 오리지널 디자인에서의 스토리지 요소의 숫자다. 전통적인 클록 로직에서는 각각의 스토리지 요소가 레지스터와 함께 실행되며, 이는 그 자신의 내부 데이터 토큰을 만든다. CE가 현재 상태 유지로 설정될 수 있기 때문에, 원래 디자인의 모든 스토리지 요소에 대해 CE는 초기 데이터 토큰을 추가하는 것으로 초기화된다. 따라서 picoPIPE 실행에서 구체화된 내부 데이터 토큰의 수는 원래 디자인과 일관성을 유지한다.
작업처리량 증가
아크로닉스 FPGA는 미립자(fine-grained) 파이프파인 단계 때문에 현존 FPGA와 비교할 때 훨씬 더 높은 작업처리량을 달성한다. 현재 있는 다른 FPGA 솔루션의 실행과는 달리, 이런 파이프라인 단계는 그 자신의 로직 기능성을 바꾸지 않고도 디자인 내 어디나 자동적으로 삽입될 수 있다.
그림 4에서 보는 것처럼, 스토리지 요소 사이에는 흔히 많은 단계의 로직이 있다. 이는 데이터가 ‘Q’ 레지스터 출력을 통과해 조합 로직을 거쳐 다음 레지스터의 ‘D’ 입력의 안정적인 상태에 정착할 때까지 시간이 걸리게 하는 요인이다. 데이터가 안정될 때까지 클록이 발생하지 않기 때문에, 클록 속도는 전체 클록 도메인 내부의 가장 긴 경로에서의 지연되는 통과 시간보다 빠를 수는 없다. 가장 긴 경로보다 짧은 모든 경로에서 데이터는 가장 긴 경로(정의상 ‘모든 경로’)를 기다려야만 한다.
그림 4. picoPIPE 대 현존 FPGA 실행
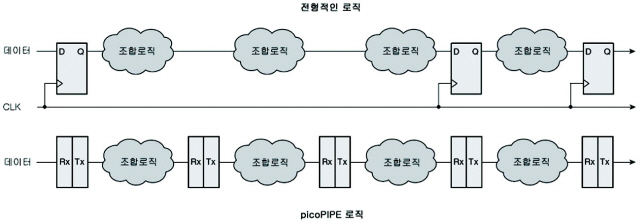
이와는 현저히 달리, picoPIPE 기술은 로직 기능성을 변화시키지 않고도 최적의 파이프라인 작업을 허용한다(그림 4). 각각의 파이프라인 단계는 로직 레벨이 적은 편이어서, 매우 빠르게 작동을 완수한다. 이는 로직을 통과하는 데이터 토큰의 비율을 증가시키며, 이는 효과적인 클록 비율을 증가시킨다(picoPIPE 기술에선 데이터 토큰이 유효한 데이터와 클록 정보와의 조합이라는 점을 기억하자).
이제 picoPIPE 기술의 장점을 아크로닉스 FPGA 내부의 물리적 레이아웃의 관점에서 고려해 보자. 전통적인 FPGA에서 신호들은 긴 라우팅 트랙을 여행해 많은 라우팅 콤포넌트를 통과한다(그림 5). 이런 신호들은 높은 용량(capacitive)의 부하(load)에서 어려움을 겪으며, FPGA가 클수록 통과해야 하는 경로도 길어진다. 덧붙여, 현재 상태 유지 요소(레지스터) 사이에는 많은 단계의 로직들이 있다.
그림 5.
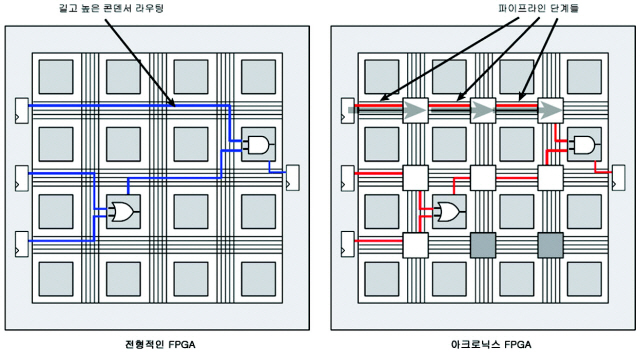
아크로닉스 FGPA 내부에서는 내장 파이프라인 작업으로 신호들이 단지 확실히 짧은 라우팅 트랙만 여행할 필요가 있다. 이는 각 단계에서 신호의 전기용량을 감소시킨다. 더 큰 디바이스에서 신호들은 여전히 디바이스의 한 코너에서 다른 쪽으로 통과해야 한다.
큰 디바이스들은 아마도 잠재적으로 약간 지연될 수는 있지만, 다른 FPGA와는 달리 이들은 작업처리량을 감소시키지 않으며, 각 파이프라인 단계에서 새로운 데이터 토큰을 유지하는데 있어 뛰어나다. 따라서 pico-PIPE 기술의 천부적인 파이프라인 작업은 FPGA가 얼마나 큰 지와는 상관없이 최고의 작업처리량이 유지되도록 해 준다. 파이프라인 작업은 데이터 토큰의 사용 비율을 훨씬 빠르게 해주며, 또한 각 파이프라인 단계마다 단지 한 개의 로직 레벨만을 둔다.
모든 사람들이 FPGA를 1.5GHz에서 운용할 필요가 있는 것은 아니다. 최소한 지금은 아니다. 최고의 작업 처리량이 필요하지 않은 곳에서 picoPIPE 기술은 현저한 대체적인 혜택을 줄 만한 몇 가지 재미있는 ‘자산’을 갖고 있다.
전력 소비는 FPGA 기반 시스템에서 흔히 있는 문제다. 많은 FPGA 솔루션이 흔히 단일 시스템에서 활용되며 이는 지나친 전력 소비로 이어진다. 아크로닉스 FPGA는 역동적인 코어 전압 스케일링을 견뎌내는 고유의 능력이 있다. 이는 성능이 감소되는 수준을 반영해서 최적의 전력 소비 상태를 유지하면서, 전압이 성능에 대한 요구가 만족되는 수준까지 낮아질 수 있도록 해 준다. 전력 소비는 전압 큐브(cube)에 비례하기 때문에, 코어 전압이 조금 감소하면 전력 소비에선 대규모 감소가 일어나게 된다.
밀도(density)는 고성능 아크로닉스 FPGA에서 현저하게 혜택을 볼 수 있는 또 다른 자산 요소다. 선천적인 고성능 혜택은 다른 솔루션의 실행이나 심지어는 ASIC RTL 솔루션의 실행과 비교할 때도 데이터 버스 대역이 좁아질 수 있도록 해 준다.
예를 들어, 현존 FPGA 솔루션은 로직 복제(replication)뿐 아니라, 시간 소비, 수동 파이프라인 단계의 삽입 등의 요소가 필요하다. 아크로닉스 FPGA는 이런 단계가 필요하지 않으며, 이는 더욱 작고 더욱 효율적인 실행이란 결과를 가져온다. 따라서, 아크로닉스 FPGA는 같은 성능에서 동등한 LUT 카운트를 하는 전통적인 FPGA 솔루션보다 큰 디자인을 포괄하는 데 있어서 뛰어나다.
더욱 높은 수준의 밀도가 TDM(Time Division Multiplexing) 테크닉을 활용하는 아크로닉스 FPGA에서도 얻어질 수 있다. 예를 들어, 65nm 스피드스터 제품군과 로직, 메모리, 증폭기 등의 1.5GHz의 원천 기능은 훨씬 효율적인 LUT 카운트를 제공하기 위해 TDM될 수 있다. 클록 사이클이 동일한 증폭기를 디바이스의 최고 성능보다 느리게 구동시킬 때, 외부 클록 사이클당 2배, 4배, 또는 심지어 8배로 일부 리소스를 활용하는 것이 가능하다.
최적의 결과를 수동 RTL 설정 없이도 얻을 수 있기 때문에, 하나의 FPGA 디자인에서 타이밍을 실행하고 종료하는 시간은 전형적인 FPGA 솔루션에 비교해 볼 때 현저히 빨라진다.
특허를 받은 picoPIPE 기술에 기반한 아크로닉스 FPGA는 다른 현존 FPGA에 비교해 볼 때, 현저한 성능상의 장점을 제공한다. picoPIPE 기술은 매우 높은 수준으로 파이프라인 돼 있으며, 현존 합성 툴로 해석될 수 있는 어떤 로직 디자인도 실행할 수 있다. picoPIPE 기술에 매핑하는 것을 통해, 디자인은 그 자신의 행동 양식을 바꾸지 않고도 파이프라인 된다.
이런 파이프라인 작업은 클록 비율을 현존 기술이 허용하는 것 이상으로 효과적으로 올려주며, 달성할 수 있는 작업처리량을 현저하게 증가시킨다. 높은 작업처리량(65nm 스피드스터 FPGA 제품군에서 1.5GHz)은 또한 더욱 낮은 전력과 증가된 밀도를 포함해서 다른 장점에 대한 좋은 조건이 될 수 있다. 아크로닉스의 획기적인 기술은 FPGA 업계에 사상 유례없는 성능을 제공하면서 프로그래밍 가능한 디바이스 기능의 새로운 시대를 알리고 있다.
출처: http://news.yeogie.com/entry/13032
![]()
![]() Send to a colleague |
Send to a colleague | ![]() Print this document
Print this document